Trace Partitioning as an Optimization Problem

Motivation
Imprecision is a very common phenomenon in static analyses that results in false alarms when used for program verification. False alarms due to imprecision are inherent to any sound tool verifying undecidable program properties. Generic refinement techniques to automatically remove false alarms to improve precision are highly desirable, as they can be adapted to a wide range of abstractions. In the last two decades, static analysis gave rise to refinement techniques to improve precision through various forms of sensitivity based on trace partitioning. Some well-known instances of trace partitioning include loop-unrolling, context-sensitivity, etc., that help improve precision of the analysis.
However, previous efforts to automatically enhance precision fall into two broad categories:
- Techniques tailored to specific abstract domains: While there is a lot of value, they require a lot of manual effort in tailoring for each abstract domain.
- Approaches based on syntactic rules or heuristics: While these techniques are generic and can be applied across many abstract domains, they are not semantic-directed, meaning they lack a general strategy for selecting which disjunctions to preserve. As a result, they rely on suboptimal heuristics to improve precision while trying to avoid path explosion. In this paper, we particularly aim to solve these limitations.
Example
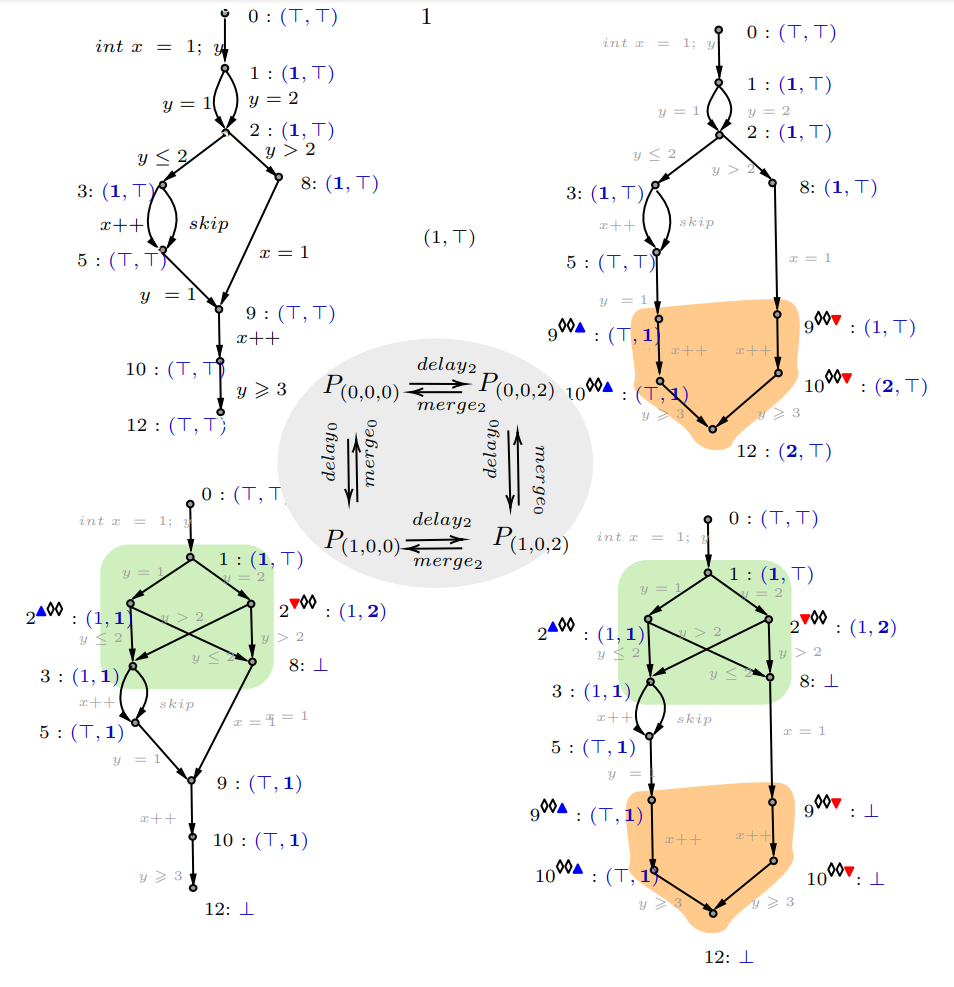
In the top left corner of the picture, we present an example program where, according to Constant Propagation (CP) analysis, error location 12 appears reachable, despite being unreachable in the actual concrete states of the program. Additionally, we illustrate three refinements of the original program through control-flow partitioning that introduce disjunctions at locations 2 and 9, to demonstrate that location 12 is indeed unreachable (⊥). While both refinements at the bottom confirm that the error is not reachable, the refinement on the bottom left is minimal in size.
For any given program, the search space of refinements is created by partitioning the control flow of the original program, and in the example, we show 3 such refinements. The largest and most precise refinement in this space is one that separates all execution traces, and this corresponds to maximal trace partitioning, which often leads to path explosion.
Goal
In this paper, we address the challenge of providing a new automatic refinement framework for static analysis, based on trace partitioning, that is generic (independent of the abstract domain) and semantic-directed. Our framework takes as input a program and uses search-based techniques to find a refinement with maximum precision in the search space of all possible refinements with regards to a given objective, while being minimal in size.
Challenges
The challenges that one faces when solving this problem are the following:
- The possibly large size of the refined programs, as program disjunctions tend to multiply, and rapidly increase the number of program paths (path explosion). The challenge here is to find one that is minimal in size without having to compute the worst-case refinement.
- The large size of the (refinement) search space, which is impossible to exhaustively explore. This is because possible precision improvements are not independent: sometimes several changes must be done simultaneously to observe a precision improvement; moreover, sometimes changing a part of the program may make a previous change in another part unnecessary (in the example, we undo the transformation at location 9 when going from bottom-right to bottom-left refinement, thus making it minimal).
- The accumulated computation time: fixpoint computation can be an expensive operation, and doing it repeatedly during the search seems to be prohibitively expensive.
- The fact that often abstract interpreters have non-monotonic operators (like widening), meaning that local improvements can actually decrease the overall precision.
- The problem of characterizing improvement: it is often possible to endlessly make a program more precise by unrolling it. Which parts of the program are worth improving, and is it better to improve these parts simultaneously, or one after the other?
Contributions
To solve the above challenges, we propose the following contributions that allow implementing a search-based method for automated program refinement and make it more efficient:
-
First, we represent the possible program refinements as tuples, where each dimension corresponds to a parameter (such as transformation locations) that can be adjusted. A higher value in any dimension signifies a program that is both larger and more precise. We maintain the relationship between these tuples and their corresponding program refinements through a homomorphism. By comparing the precision of the program refinements at specific locations of interest, we optimize the process. These tuples form the foundation of our ratchet search strategy, which alternates between phases focused on enhancing precision and those aimed at reducing program size within the same precision level, while also pruning the search space by skipping regions that would reduce precision.
-
We implement incremental computation to avoid recomputing the full fixpoint when testing a new program refinement. Computing incremental program refinement derives from the homomorphism, and we discuss different optimizations to improve the incremental fixpoint computations. We use a modified incremental fixpoint computation as a way to force monotonicity of the refinement process for non-monotonic abstract operators, i.e., our incremental fixpoint computation is more precise than recomputing the fixpoint from scratch and guarantees that further refining a program cannot decrease the precision.
-
We provide a reference implementation of our search algorithm and prove some properties about it. In particular, given a bound on our search space, our algorithm guarantees that it can return a maximally precise program with minimal size within that bound. We also provide search strategies to quickly find suitable program refinements: Iterative Deepening Depth-First Delay Search (IDDDS) and Synchronized Delay Search (SDS), the latter mimicking common trace-partitioning heuristics.
-
We implement our framework on top of existing abstract domain libraries and evaluate it on 1126 examples from the SVComp benchmark, demonstrating both its feasibility and its interest. It performs better than standard baselines (no trace partitioning, full trace partitioning, SDS-partitioning), explores only a small fraction of the refinement space while finding complex refinements of interest (e.g., with refinement depth up to 160).
-
Finally, there is a large gap between problematic issues in theory and how well they work in practice. We report on the important experimental points that make our approach practical.
Further information
- Read the paper
- To appear at the 31st Static Analysis Symposium (SAS 2024)
- Artifact (to be included in Codex in a near future!)